

How To Print A Register Value After Ptrace
Consignment 3: Working with Processes
This handout was adapted from material by Jerry Cain, Nick Troccoli, and Chris Gregg.
We've progressed through a good corporeality of material involving processes and synchronization. In this assignment, you'll implement ii small-ish programs that will exercise your understanding of concurrency, synchronization, and inter-procedure communication. You can get the starter code by typing the following:
git clone /usr/class/cs110/repos/assign3/$USER assign3 Due Date: Tuesday, July xx, 2021 at 11:59pm pacific time
Program 1: trace
In this office of the assignment, you'll implement a debugging utility that allows you to intercept and brandish the system calls that a process makes.
What is trace?
Recall that a procedure is sort of similar an unprivileged box in which a sequence of assembly instructions executes:

The plan tin can freely work with anything inside the box (variables, functions, etc.), but any time information technology wants to interact with the outside world, it must use a system call to do and so.
Virtually debugging techniques you lot've encountered so far focus on debugging within the box. What functions are being chosen? What is the value of variables? Which if statements are executing? This works great in a controlled surroundings: when you're able to run and re-run the program on your own car with different inputs, when you're running an unoptimized binary with debugging symbols available, when you're able to step through with breakpoints or add print statements, and so on.
However, debugging production applications can be less forgiving. Production applications are by and large compiled at high optimization levels with no debugging symbols included, which tin make it very hard to step through the lawmaking being executed. It's often not possible to step through code in gdb or add impress statements when the failing application is running on some remote server instead of your local machine. Peradventure you lot're even trying to reverse engineer what some software (or maybe some malware) does, in a situation where you don't have whatsoever source lawmaking available and the original authors tried to obfuscate what the binary is doing.
In these cases, sometimes information technology is helpful to have a different arroyo to debugging: instead of trying to await at everything happening inside the box, we can observe how the box is interacting with the outside globe, so nosotros apply that information to effigy out what'due south going on. It's similar the old thought experiment: "If a tree falls in a forest and no ane is around to hear it, does information technology brand a audio?" If a program has a bug but never makes any system calls to expose that issues to the outside world, does it really have a problems? Probably non, at least not one that we care about. Every interaction with the outside world must happen through syscalls, therefore by observing how a program interacts with the world, nosotros can identify the specific behaviors that are causing problems without needing to follow everything happening inside the box.
Diverse trace programs let us do this. Linux has strace, Mac has dtrace, and Windows has its ain suite of tools. In this assignment, you'll implement a program with all of the core functionality that strace has!
Sample execution
Consider, for example, the following nonsense program (drawn from simple-test5.cc in your assign3 repo).
int main(int argc, char *argv[]) { write(STDOUT_FILENO, "12345\n", 6); int fd = open(__FILE__, O_RDONLY); write(fd, "12345\north", 6); close(fd); read(fd, NULL, 64); close(/* bogusfd = */ yard); render 0; } A simple trace of the command ./simple-test5 might await like this:
$ ./trace --simple ./elementary-test5 syscall(59) = 0 syscall(12) = 14434304 // many lines omitted for brevity syscall(1) = 12345 6 syscall(2) = 3 syscall(1) = -9 syscall(3) = 0 syscall(0) = -9 syscall(3) = -9 syscall(231) = <no return> Programme exited commonly with status 0 It may look like a bunch of random numbers, but the numbers in parentheses are organisation call opcodes (59 is the opcode for execve, 12 is for brk, 1 is for write, ii is for open, iii is for close, 0 is for read, and 231 is exit_group) and the numbers after the equals signs are return values (that 6 is the number of characters just published by write, the -9's communicate write's, read'south, and close's inability to office when handed closed, incompatible, or otherwise bogus file descriptors, and exit_group never returns).
When run in elementary fashion, these CPU snapshots are printed without much translation. Y'all'll too implement a full way in which trace displays the same system calls but with much more detailed data - the annals values are translated to full system call names, strongly typed argument lists (eastward.thousand., ints, C strings, pointers), and properly interpreted render values:
$ ./trace ./simple-test5 execve("./simple-test5", 0x7fff725831e0, 0x7fff725831f0) = 0 brk(NULL) = 0xd4b000 // many lines omitted for brevity write(ane, "12345 ", 6) = 12345 vi open up("elementary-test5.cc", 0, 6) = 3 write(3, "12345 ", five) = -ane EBADF (Bad file descriptor) close(iii) = 0 read(3, Zip, 64) = -1 EBADF (Bad file descriptor) close(1000) = -1 EBADF (Bad file descriptor) exit_group(0) = <no render> Program exited normally with condition 0 You can meet the return values, if negative, are e'er -ane. When the return value is -1, the value of errno is printed later on that in #define constant form (e.g. EBADF), followed past a specific error message in parentheses (e.g. "Bad file descriptor"). If the return value is nonnegative, then that return value is simply printed and errno is ignored equally irrelevant.
Real-world usage
trace is an invaluable tool for debugging production systems. This weblog post by Julia Evans provides an excellent list of different use cases. (Her blog is as well filled with many other gems for learning about computer systems.)
How practise syscalls work?
Nosotros have been talking about how the kernel is the i that executes the code implementing syscalls (e.k. when you lot call write(), it's the kernel talking to the disk on your behalf). Regular programs don't accept the power to execute the special associates instructions or access special registers for interacting with hardware, controlling virtual retentiveness, or any of the other things the kernel can practise. We as well mentioned how the kernel executes its code within its own virtual address space, preventing ordinary programs from seeing this retention.
How does this work? How does the CPU switch from user/unprivileged mode to kernel/privileged mode, and how does it switch from running ordinary program lawmaking to running code that'south role of the kernel?
When you call a syscall such as write(), the post-obit things happen:
- The implementation of the syscall function (east.grand.
write) sets the annals%raxto an opcode, which is a number indicating which system telephone call nosotros're trying to run. Yous tin can find a list of opcodes hither. In improver, the parameters for the syscall are placed in the registers%rdi,%rsi,%rdx,%r10,%r8, and%r9, in that order. - The syscall function executes the instruction
int 0x80. Theintinstruction performs a "software interrupt," which transfers control to an "interrupt handler" in the kernel. There are many different kinds of interrupts (eastward.g. when you segfault or split by cipher, control flow jumps to a handler that prints an error and terminates the plan). The interrupt0x80is the arrangement call interrupt, and when your program runsint 0x80, the CPU switches into kernel mode and starts running the kernel function that handles system calls. - The kernel system call interrupt handler looks at
%raxto see which system phone call the program was trying to execute, and calls the appropriate function within the kernel. The kernel places the return value dorsum into the%raxregister, then runs thesysretqinstruction to switch dorsum into user/unprivileged manner. Our program picks up where it left off, right later theint 0x80instruction.
If you're curious for more than details, this page has an splendid overview of everything that happens in the kernel, with lots of links to kernel source code.
How does trace work?
Implementing trace will involve working with 2 processes. The kid process will be used to execute the program nosotros wish to observe (e.thousand. ./uncomplicated-test5). The parent process volition follow its execution, printing out each syscall that the child makes.
At the heart of trace is a system phone call named ptrace. A quick glance at ptrace'due south human page provides the following:
The ptrace organisation call provides a means by which one process (the "tracer") may detect and control the execution of another procedure (the "tracee"), and examine and modify the tracee'south memory and registers. It is primarily used to implement breakpoint debugging and system call tracing.
This is a really, really, really complicated syscall that tin do a lot of things (information technology's also how GDB is implemented!), but we'll break downward how it works here.
The prototype of ptrace looks like this:
long ptrace(enum __ptrace_request request, ... other arguments ...); This is actually several functions bundled into one. The first argument is a constant indicating what y'all want to do (due east.k. PTRACE_TRACEME, PTRACE_PEEKUSER, PTRACE_SYSCALL, etc.), and based on this constant, other arguments might be required.
There are four commands that are important for implementing trace:
-
ptrace(PTRACE_TRACEME)should be called in the kid process, before starting to execute the program nosotros want to trace, to tell the kernel that information technology wants its parent process to be able to observe its execution. - When the tracing starts, the child process will be paused (as in
SIGSTOPpaused; information technology will not continue until it receivesSIGCONT).ptrace(PTRACE_SYSCALL, pid_t pid, 0, 0)should be called in the parent procedure, which volition shipSIGCONTto the child to wake it upwards, but will pause the kid again every bit before long as information technology reaches a syscall boundary. You lot can think of a syscall purlieus like the speech bubbling in the picture higher up:PTRACE_SYSCALLwill pause the child correct when information technology asks the kernel to do something, and right when the kernel finishes running the syscall. -
ptrace(PTRACE_PEEKUSER, pid_t pid, REGISTER_NAME * sizeof(long))is called in the parent process in gild to read a register value from inside the child procedure.ptracewill return the value of the register equally along. -
ptrace(PTRACE_PEEKDATA, pid_t pid, void *address_to_read)is called by the parent to read along(8 bytes) fromaddress_to_readin the child's virtual address infinite.ptracereturns the value that was read as along.
Tracing generally goes like follows:
- The child uses
PTRACE_TRACEMEto tell the kernel that it wants to be traced, and then goes to sleep until the parent process is set up to start tracing. Once everything is fix, the child callsexecvpto start running the programme we want to trace (east.thou../simple-test5). - The parent waits for the child to be set up. Then, it uses
PTRACE_SYSCALLto wake upwardly the child and waits until the child makes a syscall. - The kernel volition interruption the kid just equally information technology'south near to brand a syscall, and it will wake up the parent. The parent uses
PTRACE_PEEKUSERandPTRACE_PEEKDATAto expect at the child procedure's registers and retentivity, figuring out which organization call is being executed and what arguments were provided. - The parent uses
PTRACE_SYSCALLonce again to run the child until the next syscall boundary (which is when the syscall is returning). - The kernel will intermission the child again just as information technology'due south returning from the syscall, and information technology will wake upwardly the parent. The parent uses
PTRACE_PEEKUSERandPTRACE_PEEKDATAonce again to get the render value of the syscall, and to readerrnofrom the child's memory if the syscall returned -1. - The parent calls
PTRACE_SYSCALLto wake up the child over again, and waits for the child to make its next syscall.
Starter Code Walkthrough
The provided starter lawmaking shows how you tin set up the kid procedure and monitor a single syscall using ptrace. When the initial version of trace.cc is compiled and invoked to profile simple-test5, nosotros see it just prints out information about the showtime arrangement telephone call:
$ ./trace --simple ./simple-test5 syscall(59) = 0 Syscall 59 is execve, which is used to implement execvp. Since execvp is the start syscall the child makes after the tracing process is fix, this is what nosotros await!
In this assignment, you'll have 2 jobs:
- Kickoff, nosotros need to extend this lawmaking to print out every syscall the child makes, from start to cease, instead of just press 1.
- Second, we need to implement the "full" mode, which prints out syscall names, arguments, and more detailed render info.
Before writing whatsoever lawmaking, make sure you truly understand what every line in the starter lawmaking does.
Handling control-line flags
Let'south walk through the starter code in main, starting with the showtime few lines (note: y'all can ignore the provided readString function for now, that will get relevant when you first implementing total trace):
int master(int argc, char *argv[]) { bool unproblematic = fake, rebuild = false; int numFlags = processCommandLineFlags(simple, rebuild, argv); if (argc - numFlags == 1) { cout << "Nothing to trace... exiting." << endl; render 0; } The starter version ignores whatever simple and rebuild are set to, even though the code you write will eventually rely on them. The implementation of processCommandLineFlags resides in trace-options.cc, and that implementation parses simply enough of the full control line to effigy out how many flags (eastward.thou. --simple and --rebuild) sit down in between ./trace and the command to be traced. processCommandLineFlags accepts simple and rebuild by reference, updating each independently depending on what command line flags are supplied. Its return value is captured in a variable chosen numFlags, and that return value shapes how execvp is invoked in the code that follows.
Setting up tracing
Adjacent, nosotros create the child process and do some work to set up tracing.
Hither'due south a graphical summary of what happens:
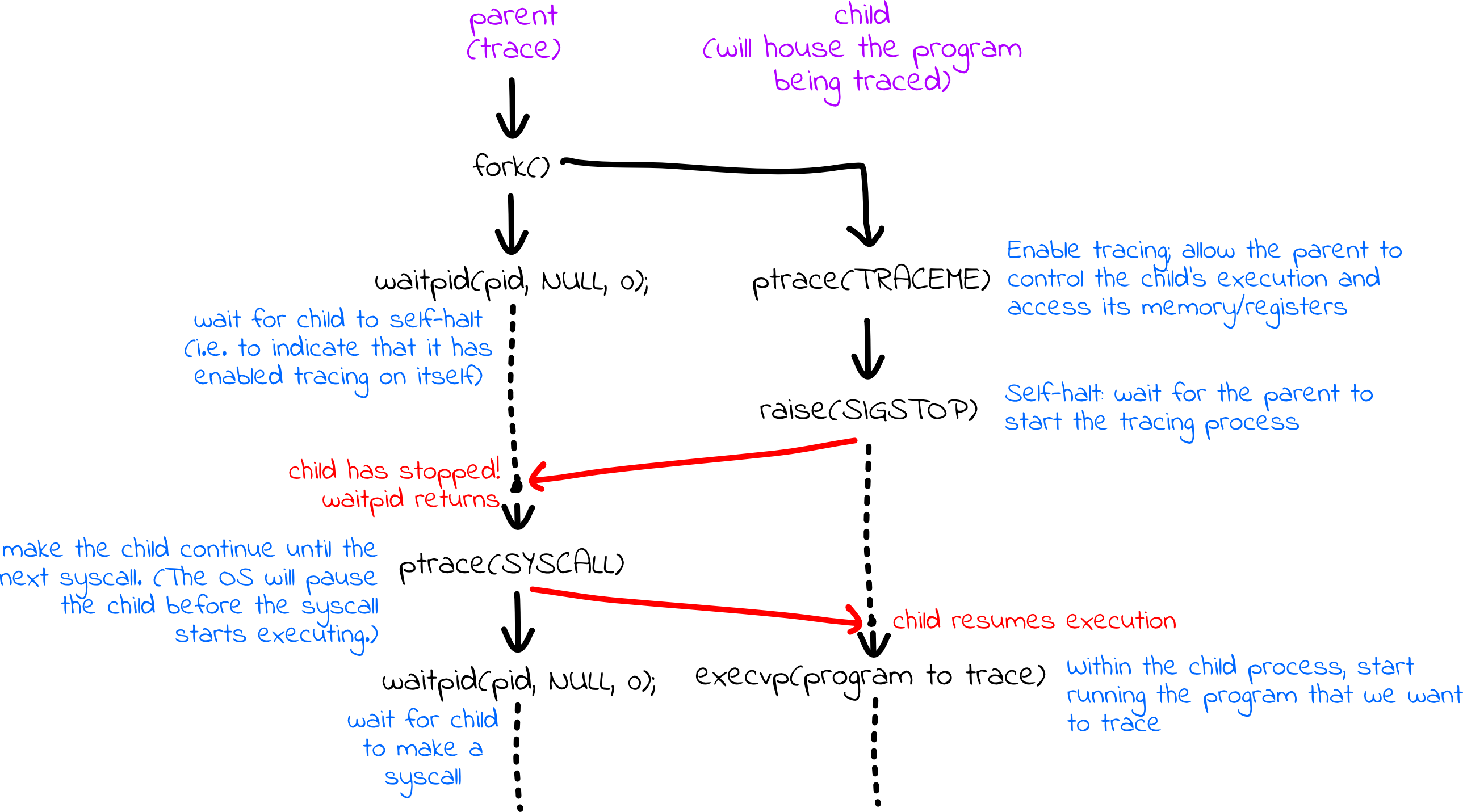
Offset, we fork off a child process that ultimately executes the programme of involvement:
pid_t pid = fork(); if (pid == 0) { ptrace(PTRACE_TRACEME); heighten(SIGSTOP); execvp(argv[numFlags + one], argv + numFlags + one); return 0; } A new process is created via fork, and the child procedure:
- calls
ptrace(PTRACE_TRACEME)to inform the Os that it's content being monitored by the parent process, - calls
heighten(SIGSTOP)and awaits parental permission to go on, and - calls
execvp(argv[numFlags + 1], argv + numFlags + 1)to transform the child process to run the command to be profiled.
We're used to seeing argv[0] and argv every bit the 2 arguments, just argv[0] is ./trace. Here, execvp'southward first argument needs to be the name of the executable to be monitored, and nosotros get to that past looking by the arguments for bodily trace. Provided the execvp succeeds, the child procedure is consumed with a new executable and proceeds through its chief role, unaware that it'll exist halted every fourth dimension information technology makes a arrangement phone call.
The return 0 at the terminate is relevant in the effect that argv[numFlags + one] names an executable that either doesn't exist or tin can't be invoked considering of permission issues. We demand to ensure the child process ends in the event that execvp fails, else its execution volition flow into lawmaking designed for the tracer, not the tracee.
Meanwhile, the parent skips the code specific to the child and executes the following lines:
int condition; waitpid(pid, &condition, 0); assert(WIFSTOPPED(status)); ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_TRACESYSGOOD); The parent (tracer) process:
- calls
waitpidto halt until the child process has granted permission to be traced and self-halted. - calls
assertto confirm that the kid self-halted - calls
ptraceto instruct the operating system to set bit 7 of the indicate number – i.e., to deliverSIGTRAP | 0x80– whenever a organisation call trap is executed. (A trap is the same thing as a software interrupt.)
The tracing process
Next, the parent and kid synchronize so that the child stops on every syscall boundary, and the parent gets a chance to audit and impress what is happening.
Here'southward a graphical summary of what happens:
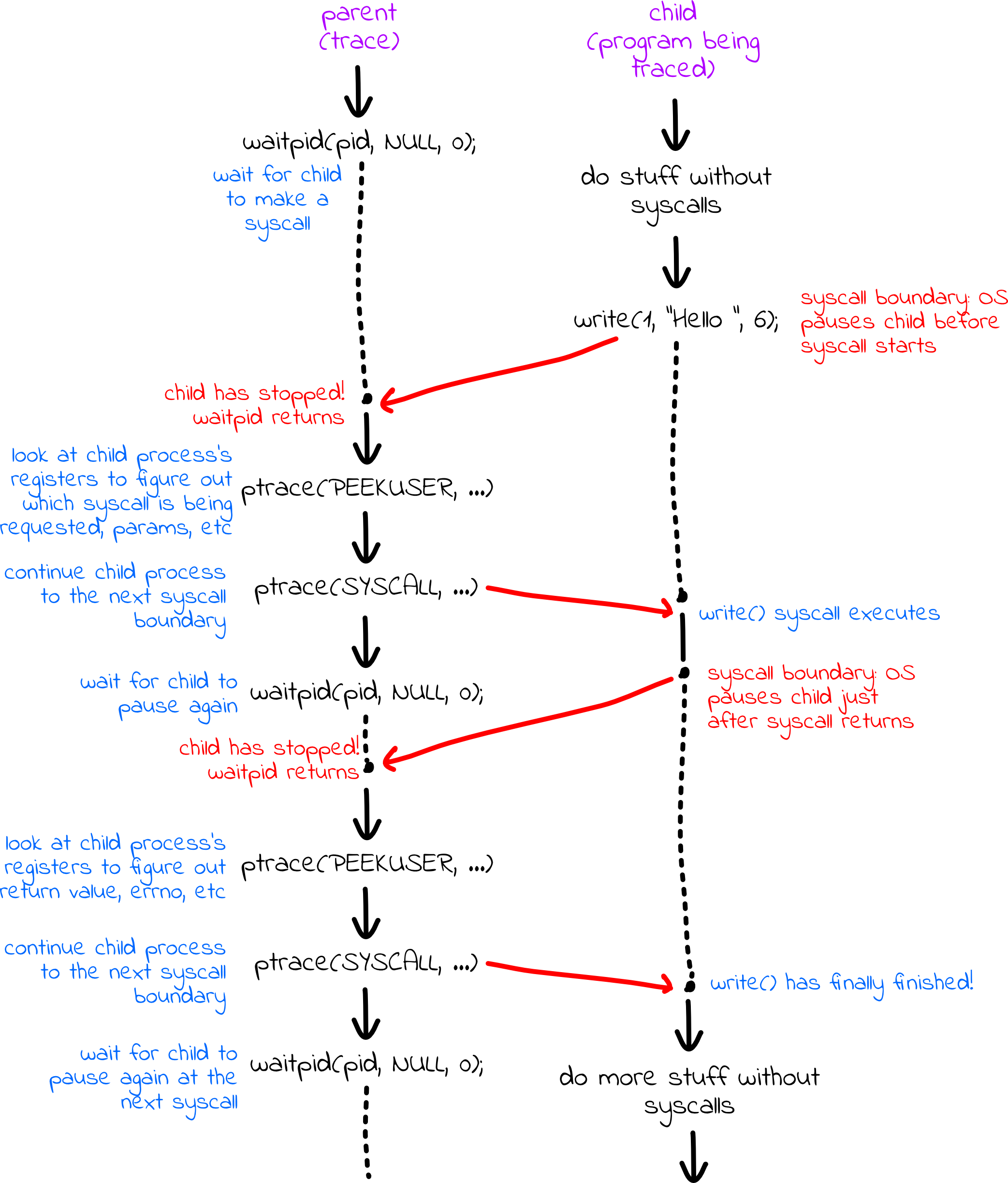
In the code, the tracer (parent) tells the tracee (kid) to proceed until it's just nearly to execute a organization call:
while (true) { ptrace(PTRACE_SYSCALL, pid, 0, 0); waitpid(pid, &condition, 0); if (WIFSTOPPED(condition) && (WSTOPSIG(status) == (SIGTRAP | 0x80))) { int num = ptrace(PTRACE_PEEKUSER, pid, ORIG_RAX * sizeof(long)); cout << "syscall(" << num << ") = " << affluent; break; } } Here's a breakup of what each line within the while loop does:
-
ptrace(PTRACE_SYSCALL, pid, 0, 0)continues a stopped tracee until it enters a system call (or is otherwise signaled). - The
waitpid(pid, &status, 0)call blocks the tracer until the tracee halts. Note:waitpidcommonly waits for processes to terminate, just if the child process has tracing enabled,waitpidwill also return when that process has stopped. This means you can phone callwaitpidseveral times on the same process. - If the tracee stops considering it's inbound a system phone call, then the
WIFSTOPPED(condition)will certainly producetruthful. If the tracee stopped because it's entering a organization call, then the tracee would be signaled withSIGTRAP | 0x80, equally per the above discussion of whatptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_TRACESYSGOOD)does. If either of the two tests&&'ed together fails, then the tracee halted for some other reason, and the tracer resumes the tracee. - Eventually, the tracee stops because information technology's entering its first system call–that is, the tracee stops just subsequently the organization phone call opcode has been placed in
%rax, whatever boosted arguments are placed in%rdi,%rsi,%rdx,%r10,%r8, and%r9, every bit needed, and the software interrupt instruction–int 0x80–has been executed. Theptrace(PTRACE_PEEKUSER, pid, ORIG_RAX * sizeof(long))is another season ofptrace, and this one extracts the value in%raxsimply as the tracee was forced off the CPU. (For reasons nosotros won't go into, the value of%raxis clobbered by the user-to-kernel fashion transition, but a pseudo-register%orig_raxpreserves the value, specifically for system call traces like we're managing hither.) - For now, nosotros are just going to get the system phone call opcode - we're ignoring system call parameters. We extract the opcode from
%orig_raxand print it withcout << "syscall(" << num << ") = " << affluent.
At this bespeak, we have printed information well-nigh what organization phone call is being made. Next, we want to print out what it returns.
while (true) { ptrace(PTRACE_SYSCALL, pid, 0, 0); waitpid(pid, &status, 0); if (WIFSTOPPED(status) && (WSTOPSIG(status) == (SIGTRAP | 0x80))) { long ret = ptrace(PTRACE_PEEKUSER, pid, RAX * sizeof(long)); cout << ret << endl; suspension;
} } This loop is extremely similar to the starting time loop. Nosotros tell the tracee to resume, and await for it to halt again, at which point we know it has just exited the organisation call. Then we extract the return value from %rax (which hasn't been clobbered–then RAX is correct, not ORIG_RAX), and print it out. Note that ret is a long instead of an int; system call render values tin can be pointers, and so all 64 bits thing. The system call opcode, however, is always pocket-size plenty to fit in an int, which is why we become with an int instead of a long in the kickoff while loop.
The rest of the starter code is placeholder and should be removed equally y'all develop a fully operational trace. Information technology exists simply to impale the tracee and look for information technology to dice before allowing the tracer to return.
kill(pid, SIGKILL); waitpid(pid, &status, 0); affirm(WIFSIGNALED(status)); render 0; That's why the starter code prints information about the get-go organisation call, but none of the others.
Office 1: Simple Trace
Your start job is to modify and build on the starter code equally needed to implement "uncomplicated" mode for trace, which prints out the total sequence of system telephone call opcodes and return values, as shown in the very first sample output above for ./trace --simple ./simple-test5. The primal claiming is yous accept no idea how many arrangement calls a monitored process makes, so you'll demand to update the code to repeatedly halt on system call enter, exit, enter, exit, and and so forth, until you notice that the tracee truly exits in the WIFEXITED sense. Equally part of this, yous should combine the 2 while loops in the starter lawmaking into one, and decompose information technology into a part that is called from 2 places (the merely reason we replicated the lawmaking in the starter trace.cc file was to simplify the discussion of how it works).
Here are some other important notes:
- You lot may assume that the traced programs are never delivered whatever non-trap signals and never execute whatever signal handlers. It wouldn't exist that much more difficult to support capricious signals and signal handlers, but it'd simply be more code that wouldn't add together much, and we haven't spent the time talking near signal handling all the same.
- Arrangement calls don't predictably return the aforementioned values with each execution, and one organization telephone call'southward render value may exist be passed equally an argument to some other system phone call downwardly the line. The
sanitycheckand theautograderare sensitive to all this–at least for the system calls relevant to the all of the test programs we've exposed–and use regular expressions that match and replace parameters and return values that are permitted, and even probable, to vary from test run to exam run. - Make certain that everything up through and including the equals sign (e.g.
syscall(231) =) is printed and flushed to the console before you allow the tracee to continue. Doing and so will help marshal your output with that of the sample executable, and will make thesanitycheckandautogradertools happy. This is of import when the system calls themselves print to the console (due east.thousand.write(STDOUT_FILENO, "12345\north", 6)), then that the system phone call output interleaves withtrace's output in a anticipated way.
Examination unproblematic mode thoroughly before moving on - you will add to this lawmaking in the side by side part, total trace.
Office two: Full Trace
Next, you will further modify this lawmaking to support "full" mode for trace; the overall architecture of the program is largely the same, just more information is printed out, as shown in the 2nd sample output above for ./trace ./uncomplicated-test5. There are 3 new main features: instead of opcodes, you volition print part names, you will also impress the function parameters, and you will print type-right render values and advisable error codes.
Role Names
How do yous convert system phone call opcodes (e.g. 59) to system phone call names (e.thousand. execve)? Nosotros provide a part compileSystemCallData, documented in trace-organization-calls.h, that populates two maps of data, the first of which contains opcode-to-name data, and is guaranteed to include every legitimate opcode every bit a primal. Each key maps to the corresponding system call name, and then that 0 maps to read, 1 maps to write, 2 maps to open up, 3, maps to close, and then forth. Y'all tin rely on the information in this map–which you should merely construct if you're running in full manner–to convert the 0's to reads and the 59's to execve's, etc. (Optionally, if you're interested, you can expect inside the implementation of compileSystemCallData within trace-system-calls.cc, and yous'll encounter that the map is congenital by parsing /usr/include/x86_64-linux-gnu/asm/unistd_64.h.)
Function Arguments
How practise you print argument lists like those contributing to execve("./unproblematic-test3", 0x7ffdd1531690, 0x7ffdd15316a0)? The same compileSystemData office populates a second map which contains organization call signature information. Nosotros tin can use this map to determine that, say, execve takes a C string and two pointers, access takes a C string followed by an integer, and that open takes a C string and ii integers. The number of arguments in the signature determines how many of the registers %rdi, %rsi, %rdx, %r10, %r8, and %r9 are relevant. The entries in the map also convey how the data in each of those registers–extracted using ptrace and PTRACE_PEEKUSER–should exist interpreted. All arguments are ints, pointers (which should be printed with a leading 0x, unless it's the zilch pointer, in which case it should be printed as Zilch), or the base accost of a '\0'-terminated character array, aka a C string. If the blazon is unknown, yous should print <unknown>. Thus, the long returned by ptrace needs to be truncated to an int, converted to a C++ string, or reinterpreted equally a void * before press it. One twist is that because the C strings reside in the tracee'south virtual accost space, we demand to use ptrace and PTRACE_PEEKDATA to extract the sequence of characters in chunks until we pull in a chunk that includes a '\0'. We take provided a consummate implementation in the starter code of a readString function that you can utilize as-is to read in a C string from the tracee's virtual address space.
Note that some system call signature information isn't hands extracted from the Linux source code, so in some cases, the system telephone call signature map populated may not include a arrangement telephone call (e.m. arch_prctl comes to listen). If the prototype information is missing from the map, print <signature-information-missing> in identify of a parameter listing, as with arch_prctl(<signature-information-missing>).
Function Return Value
How exercise yous print out return value information according to its type, along with a corresponding fault code, if any? If the render value was from…
-
brkormmap: print that value as a 64-bit pointer, with a leading0x - NOT
brkormmap, and the raw render value is…- nonnegative: impress that value as an
int - negative: print as -1, and after that synthesize and print the equivalent errno #define constant (e.g.
EBADForENOENT) and the corresponding error cord, which is produced by a call tostrerror. Note that the realerrnoglobal hasn't been set up only yet; that comes a few instructions after the organisation call exits. But you tin can hands compute whaterrnowill soon be (and what should be printed past trace) by taking the absolute value of the raw render value and using that.
- nonnegative: impress that value as an
For negative values, how practise you convert the computed errno values to the synthesized values? We provide a office compileSystemCallErrorStrings, documented in trace-error-constants.h, that populates a map of information containing errno-to-proper name information (again, the errno value is the absolute value of the raw return value). A raw render value of -ii, for case, becomes "ENOENT", and a raw return value of -ix (which we run across a agglomeration in the simple trace of simple-test5) becomes "EBADF". (Optionally, if you're interested, you tin can await within the implementation within trace-error-constants.cc). Then, you can use strerror, which too takes an errno value, to get the corresponding error message; e.g. strerror(2) and strerror(9) return "No such file or directory" and "Bad file descriptor", respectively. Check out the man page for strerror for more information.
If a system call was made, just before returning the tracee finishes running, then you tin cease looping and print <no return>.
With these pieces in place, your trace executable should take a fully-functional "full" style!
ptrace Constants Reference
The full list of ptrace constants we use for our own solution are presented right hither:
-
PTRACE_TRACEME: Used by the tracee to state its willingness to exist manipulated and inspected by its parent. No additional arguments are required, and then a simple call toptrace(PTRACE_TRACEME)does the play tricks. -
ptrace(PTRACE_SYSCALL, pid, 0, 0)instructs a stopped tracee to go along executing as usual until it either exits, is signaled, is caught entering a organization call, or is caught exiting i. The tracer relies onwaitpidto block until the tracer stops or exits. -
ptrace(PTRACE_SETOPTIONS, pid, 0, PTRACE_O_TRACESYSGOOD)instructs the kernel to set up bit 7 of the wait status to be 1 for allSIGTRAPs associated with a tracee'due south organization call. -
PTRACE_PEEKUSER: Used by the tracer to audit and excerpt the contents of a tracee'southward register at the time of the telephone call. Simply the showtime three arguments are needed, and any value passed throughdatais ignored. A phone call toptrace(PTRACE_PEEKUSER, pid, RSI * sizeof(long)), for example, returns the contents of the tracee's%rsiregister at the time of the phone call (provided the suppliedpidis the process id of the tracee, of grade). There are constants for all registers (RAX,RSI,RBX,RSP, etc), and the 3rd argument is supposed to be scaled past the size of a give-and-take on that processor (which is, by definition, the size of along). -
PTRACE_PEEKDATA: Used by the tracer to inspect and excerpt the discussion of data residing at the specified location within the tracee's virtual address space. A telephone call toptrace(PTRACE_PEEKDATA, pid, 0x7fa59a8b0000)would return the eight bytes residing at accost0x7fa59a8b0000within the tracee'due south virtual address space, and a telephone call toptrace(PTRACE_PEEKDATA, pid, ptrace(PTRACE_PEEKUSER, pid, RDI * sizeof(long))would return the eight bytes residing at another address, which itself resides in%rdi). If you know the contents of a annals is an address interpretable as the base address of a'\0'-terminated C cord, you can collect all of the characters of that string past a sequence ofPTRACE_PEEKDATAcalls, as implied by the partial implementation ofreadStringwe shared above.
Last Notes
- The very get-go time yous run trace, you should expect it to accept a while to read in all of the prototype data for the linux kernel source tree. All of the epitome information is cached in a local file later on that (the cache file volition sit in your repo with the proper name
.trace_signatures.txt), so trace will fire up much more quickly the second time. Should you want to rebuild the prototype cache for whatsoever reason, you can invoke trace with the--rebuildflag, as with./trace --rebuild ./simple-test5. - The return value of
traceis always the return value of the tracee. Running the sample executable onsimple-test3should make it clear what nosotros're expecting. Note that you're responsible for printing the concluding line ("Plan exited normally…"). If an error occurs that causestraceto finish early, information technology'southward ok to cease with a different status lawmaking. - Yous don't need to do comprehensive error checking, but you may practice so to help better the robustness of your solution or to catch functionality issues as you're working.
Program ii: Implementing farm in C++
Your final challenge is to harness the power of a computer'southward multiple cores to manage a collection of processes, each running in parallel to contribute its share to a larger result. For the purposes of this problem, we're going to contrive a scenario where the computation of interest – the prime number factorization of arbitrarily large numbers – is complex plenty that some factorizations take multiple seconds or even minutes to compute. The factorization algorithm itself isn't the focus here, salve for the fact that it's potentially time consuming, and that should we need to compute multiple prime factorizations, we should leverage the computing resources of our trusty myth cluster to multiprocess and generate output more quickly.
Consider the following Python program called cistron.py:
self_halting = len(sys.argv) > 1 and sys.argv[one] == '--cocky-halting' pid = os.getpid() while True: if self_halting: os.kill(pid, signal.SIGSTOP) try: num = int(raw_input()) # raw_input blocks, somewhen returns a single line from stdin except EOFError: break; # raw_input throws an EOFError when EOF is detected kickoff = time.time() response = factorization(num) stop = time.time() print ' %s [pid: %d , time: %g seconds]' % (response, pid, end - start) You really don't need to know Python to understand how it works, because every line of this item program has a articulate C or C++ analog. The master things I'll point out are:
- Python's
printoperates just similar C'sprintf(and it'south even procedure-safe) -
raw_inputreads and returns a single line of text from standard input, blocking indefinitely until a line is supplied (chomping the'\n') or until cease-of-file is detected -
factorizationis something I wrote; it takes an integer (eastward.grand.12345678) and returns the prime factorization (eastward.g.12345678 = 2 * 3 * 3 * 47 * 14593) as a string. You'll run across it when you open upfactor.pyin your favorite text editor. - The
os.impaleline prompts the script to cease itself (but merely if the script is invoked with the'--self-halting'flag) and expect for information technology to be restarted viaSIGCONT
The post-obit should convince you our script does what you'd await:
$ printf "1234567\n12345678\n" | ./gene.py 1234567 = 127 * 9721 [pid: 28598, time: 0.0561171 seconds] 12345678 = 2 * 3 * 3 * 47 * 14593 [pid: 28598, time: 0.512921 seconds] $ time printf "1234567\n12345678\n123456789\n1234567890\north" | ./factor.py 1234567 = 127 * 9721 [pid: 28601, time: 0.0521989 seconds] 12345678 = 2 * 3 * 3 * 47 * 14593 [pid: 28601, fourth dimension: 0.517912 seconds] 123456789 = 3 * 3 * 3607 * 3803 [pid: 28601, fourth dimension: 5.18094 seconds] 1234567890 = 2 * 3 * 3 * 5 * 3607 * 3803 [pid: 28601, time: 51.763 seconds] existent 0m57.535s user 0m57.516s sys 0m0.004s $ printf "1001\n10001\n" | ./factor.py --self-halting $ impale -CONT %1 1001 = seven * eleven * 13 [pid: 28625, time: 0.000285149 seconds] $ kill -CONT %1 10001 = 73 * 137 [pid: 28625, fourth dimension: 0.00222802 seconds] $ impale -CONT %1 $ kill -CONT %1 -bash: kill: (28624) - No such procedure $ time printf "123456789\n123456789\north" | ./factor.py 123456789 = 3 * 3 * 3607 * 3803 [pid: 28631, fourth dimension: five.1199 seconds] 123456789 = 3 * 3 * 3607 * 3803 [pid: 28631, fourth dimension: 5.1183 seconds] existent 0m10.260s user 0m10.248s sys 0m0.008s This concluding examination may look light-headed, just information technology certainly verifies that ane process is performing the same factorization twice, in sequence, so that the overall running time is roughly twice the time it takes to compute the factorization the first time (no caching here, and then the second factorization does it all over again).
Our factorization part runs in O(n) time, then it's very slow for some large inputs. Should you need to compute the prime factorizations of many big numbers, the factor.py script would become the job washed, only it may take a while. If, even so, you're ssh'ed into a auto that has multiple processors and/or multiple cores (each of the mythsouth has eight cores), you tin write a program that manages several processes running factor.py and tracks which processes are idle and which processes are deep in thoughtful number theory.
You're going to write a programme – a C++ program chosen farm – that tin can run on the myths to leverage the fact that y'all accept eight cores at your fingertips. subcontract will spawn several workers – ane for each core, each running a self-halting case of factor.py, read an unbounded number of positive integers (1 per line, no fault checking required), forrard each integer on to an idle worker (blocking until one or more than workers is gear up to read the number), and allow all of the workers to cooperatively publish all prime factorizations to standard output (without worrying near the order in which they're printed). To illustrate how farm should work, check out the following exam example:
$ time printf "1234567890\n1234567890\n1234567890\n1234567890\n1234567890\n1234567890\n1234567890\n1234567890\due north" | ./subcontract In that location are this many CPUs: 8, numbered 0 through 7. Worker 4245 is set to run on CPU 0. Worker 4246 is set to run on CPU one. Worker 4247 is set to run on CPU 2. Worker 4248 is set to run on CPU 3. Worker 4249 is set to run on CPU 4. Worker 4250 is set to run on CPU 5. Worker 4251 is set to run on CPU 6. Worker 4252 is ready to run on CPU vii. 1234567890 = 2 * 3 * 3 * 5 * 3607 * 3803 [pid: 4249, time: 95.5286 seconds] 1234567890 = 2 * 3 * iii * 5 * 3607 * 3803 [pid: 4252, time: 95.5527 seconds] 1234567890 = two * three * 3 * 5 * 3607 * 3803 [pid: 4245, time: 95.5824 seconds] 1234567890 = 2 * three * 3 * 5 * 3607 * 3803 [pid: 4247, time: 95.5851 seconds] 1234567890 = ii * 3 * iii * five * 3607 * 3803 [pid: 4248, fourth dimension: 95.6578 seconds] 1234567890 = 2 * three * 3 * five * 3607 * 3803 [pid: 4250, time: 95.6627 seconds] 1234567890 = ii * 3 * three * 5 * 3607 * 3803 [pid: 4251, time: 95.6666 seconds] 1234567890 = 2 * 3 * three * 5 * 3607 * 3803 [pid: 4246, time: 96.254 seconds] existent 1m36.285s user 12m42.668s sys 0m0.128s Note that each of eight processes took nigh the same amount of time to compute the identical prime factorization, simply because each was assigned to a different core, the existent (aka perceived) time is basically the time it took to compute the factorization just once. How'south that for parallelism!
Notation that prime factorizations aren't required to be published in order – that makes this all a little easier – and repeat requests for the same prime number factorization are all computed from scratch.
Your subcontract.cc implementation volition make use of the following C++ tape, global constants, and global variables:
static const size_t kNumCPUs = sysconf(_SC_NPROCESSORS_ONLN); static vector<subprocess_t> workers(kNumCPUs); The principal role nosotros give yous includes stubs for all of the helper functions that decompose it, and that principal function looks similar this:
int main(int argc, char *argv[]) { spawnAllWorkers(); broadcastNumbersToWorkers(); waitForAllWorkers(); closeAllWorkers(); render 0; } This final problem can be tricky, but it's perfectly manageable provided you follow this road map:
- Offset implement
spawnAllWorkers, which spawns a self-haltingcistron.pysubprocess for each cadre and adds thesubprocess_tstruct to the globalworkersvector. Yous'll desire to have a expect at thesubprocess.hfile to see how thesubprocess()function works. Each subprocess should executefactor.pyas specified bykWorkerArguments; we desire to supply input to each child (i.due east. numbers to factor), but nosotros practice not want to process the output of each child (the output will go straight to the terminal instead). You will need to assign each process to always execute on a particular core by leveraging functionality outlined in theCPU_SETandsched_setaffinityman pages (i.e. type inmanCPU_SETto larn nearly thecpu_set_ttype, theCPU_ZEROandCPU_SETmacros, and thesched_setaffinityfunction). - Implement a
getAvailableWorkerhelper office, which you lot'll utilize to decompose thebroadcastNumbersToWorkersfunction in the side by side step. This function should expect until a worker has self-halted (i.e. sent itselfSIGSTOP), indicating that it is gratuitous to do work. Once a worker is bachelor, this office should render itssubprocess_tstruct from theworkersvector. - Flesh out the implementation of
broadcastNumbersToWorkers. This function reads numbers from stdin and should distribute the numbers beyond thefactor.pykid processes. Once you lot've read a number, you should transport it to an bachelor worker by writing it to that worker's input piping (usedprintf) and wake upwardly the worker past sendingSIGCONT. When writing the number into a pipe, don't forget to include a newline so that the child can tell when information technology has finished reading all of the digits in a number. - Implement
waitForAllWorkers, which does more or less what it says – it waits for all workers to self-halt and become bachelor. - Last merely not least, implement the
closeAllWorkersroutine to coax all workers to exit by closing their input pipes and waking them up and so they see that the input piping has been closed. Finally, wait for them to all go out and ensure no zombie processes are left behind.
Your implementation should not make whatsoever invalid retentiveness accesses or cause any segfaults, and nothing you write should orphan any memory. (Y'all shouldn't need to utilise malloc or new.) Don't leak file descriptors (other than 0, 1, and 2), and don't exit zombie processes behind.
Submitting your work
Once you lot're done, you should run ./tools/sanitycheck all of your piece of work as you normally would and and then run ./tools/submit.
Automated style checks
Nosotros are experimenting with including an automated manner checker called clang-tidy. This is an manufacture-standard tool that can take hold of many common pitfalls such as forgetting to initialize variables, leaking memory, and much more. At that place is a full listing of checks here, although we are only using a subset of them.
To run clang-tidy on trace and farm, you lot can run make tidy. If you detect that clang-tidy is complaining about things you call up aren't a existent problem, please permit us know, and we'll either explicate why the cheque is of import or we'll remove the check for the future.
Nosotros have likewise included these checks in sanitycheck. For now, we won't run clang-tidy as function of functionality grading or assign its output any points. That being said, many of the problems clang-tidy are related to functionality, and we may deduct for stylistic issues during way grading, then we highly recommend aiming for a clean tidy output.

How To Print A Register Value After Ptrace,
Source: https://web.stanford.edu/class/cs110/summer-2021/assignments/assign3-multiprocessing/
Posted by: salothisheatch59.blogspot.com
0 Response to "How To Print A Register Value After Ptrace"
Post a Comment